
Press Ctrl+ and K to search
请注意,本文编写于 45 天前,最后修改于 43 天前,其中某些信息可能已经过时。
目录
一、hdfs测试
HDFS 基础操作(验证存储功能)
核心验证:HDFS 能创建目录、上传 / 下载文件、查看文件内容、删除文件,代表 HDFS 存储链路正常。
js# 在HDFS根目录下创建test目录(HDFS路径以/开头)
hadoop fs -mkdir /test
# 验证目录创建成功
hadoop fs -ls /
# 输出中能看到 drwxr-xr-x - root supergroup 0 2025-12-20 05:00 /test
js# 在本地(服务器)创建一个文本文件,写入测试内容
echo "Hello Hadoop
Hello MapReduce
Hello YARN
Hadoop is cool" > /tmp/test.txt
# 查看本地文件内容(确认无误)
cat /tmp/test.txt
# 把本地/tmp/test.txt上传到HDFS的/test目录下
hadoop fs -put /tmp/test.txt /test/
# 验证上传成功
hadoop fs -ls /test
# 输出:-rw-r--r-- 1 root supergroup 56 2025-12-20 05:01 /test/test.txt
# 读取HDFS中test.txt的内容(验证能正常读取)
hadoop fs -cat /test/test.txt
# 输出和本地文件一致:
# Hello Hadoop
# Hello MapReduce
# Hello YARN
# Hadoop is cool
# 先删除本地/tmp/test_download.txt(避免冲突)
rm -rf /tmp/test_download.txt
# 从HDFS下载/test/test.txt到本地/tmp/test_download.txt
hadoop fs -get /test/test.txt /tmp/test_download.txt
# 验证下载的文件内容
cat /tmp/test_download.txt
# 内容和原文件一致则正常
MapReduce 经典 WordCount(验证计算功能)
核心验证:YARN 资源调度正常、MapReduce 计算框架能运行,代表 Hadoop 计算链路正常(这是 Hadoop 最经典的入门案例,统计文本中单词出现次数)。
js# 1. 本地创建更丰富的测试文件
echo "apple banana apple
banana orange apple
orange grape" > /tmp/wordcount.txt
# 2. 重新创建HDFS目录并上传文件
hadoop fs -mkdir /wordcount
hadoop fs -put /tmp/wordcount.txt /wordcount/
# 3. 验证上传成功
hadoop fs -cat /wordcount/wordcount.txt
执行 WordCount 计算(调用 Hadoop 自带的示例 Jar 包)
js# 核心命令:hadoop jar <示例Jar包路径> <WordCount类名> <输入路径> <输出路径>
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /wordcount/wordcount.txt /wordcount/output
# 执行过程会输出大量日志,关键看最后是否有 "Job job_xxxx completed successfully" 提示
注意
输出路径 /wordcount/output 必须不存在(Hadoop 禁止覆盖已有目录,否则报错);
若报错 “找不到 Jar 包”,检查 Jar 包路径:ls $HADOOP_HOME/share/hadoop/mapreduce/ 确认 hadoop-mapreduce-examples-3.3.6.jar 存在。
查看 WordCount 计算结果
js# 查看输出目录下的结果文件(MapReduce的输出会拆分成part-r-00000)
hadoop fs -cat /wordcount/output/part-r-00000
# 正常输出(单词+出现次数):
apple 3
banana 2
grape 1
orange 2

二、hdfs伪分布模式
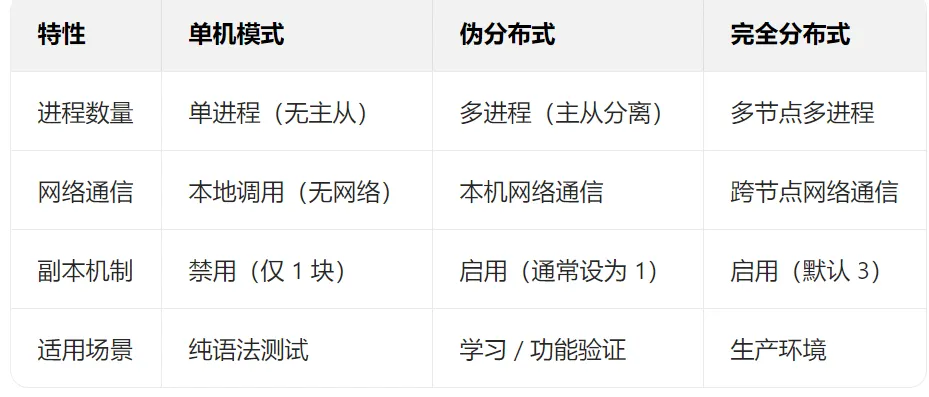
HDFS 伪分布式(Pseudo-Distributed)是单节点模拟分布式 HDFS 集群的部署模式 —— 所有 HDFS 核心进程(NameNode、DataNode、SecondaryNameNode)都运行在同一台服务器上,但进程间通过网络通信、按分布式逻辑协作(区别于 “单机模式” 的单进程运行)。
修改 core-site.xml(HDFS 核心配置)
jsvi /opt/hadoop/hadoop-3.3.6/etc/hadoop/core-site.xml
js<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!-- 指定HDFS的默认访问地址(主机名对应你的k8s-Master01) -->
<name>fs.defaultFS</name>
<value>hdfs://192.168.201.100:9820</value>
</property>
<property>
<!-- HDFS临时目录(需确保root有读写权限) -->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-3.3.6/tmp</value>
</property>
</configuration>
修改 hdfs-site.xml(HDFS 副本 / 端口配置)
jsvi /opt/hadoop/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
js<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!-- 副本数设为1(伪分布式只有1个DataNode,设3会报错) -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.201.100:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.201.100:9870</value>
</property>
</configuration>
修正 hadoop-env.sh(指定 Java 路径 + 用户)
jsvi /opt/hadoop/hadoop-3.3.6/etc/hadoop/hadoop-env.sh
最后末尾添加
js# 指定Java路径(你的软链接已解决路径问题)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
# 指定root用户运行HDFS进程
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export HADOOP_OPTS="$HADOOP_OPTS -Duser.language=zh -Duser.region=CN"
修改workers
jsvi /opt/hadoop/hadoop-3.3.6/etc/hadoop/workers
覆盖修改
jsk8s-master01
自身免密登录
js# 1. 进入 Root 家目录(确保路径正确)
cd ~
# 2. 删除旧的 SSH 密钥(避免冲突)
rm -rf ~/.ssh/*
# 3. 重新生成 SSH 密钥(一路回车,不设置密码)
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
# 4. 将公钥添加到授权列表(关键!)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 5. 强制修正权限(SSH 对权限极其敏感,必须严格设置)
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
chown root:root -R ~/.ssh
# 6. 关闭 SSH 的 GSSAPI 认证(避免干扰免密登录)
sed -i 's/GSSAPIAuthentication yes/GSSAPIAuthentication no/g' /etc/ssh/ssh_config
sed -i 's/GSSAPIDelegateCredentials yes/GSSAPIDelegateCredentials no/g' /etc/ssh/ssh_config
验证 SSH 免密登录(必须通过!)
js# 验证1:登录本机主机名(小写 k8s-master01)
ssh k8s-master01 "echo success"
# 正常输出:success(无需输入密码,首次需输入 yes 确认)
# 验证2:登录 localhost
ssh localhost "echo success"
# 正常输出:success
# 验证3:(若仍有大写主机名残留)登录 k8s-Master01(临时兼容)
ssh k8s-Master01 "echo success"
格式化 HDFS(仅首次执行!)
js# 确保当前目录有效(如/root或/)
cd /root
# 格式化NameNode(初始化HDFS元数据)
hdfs namenode -format
# 成功标志:最后输出 "Exiting with status 0"
# ❗ 注意:重复格式化会清空HDFS所有数据,测试环境也需谨慎
启动 HDFS 伪分布式集群
js# 启动HDFS所有进程(NameNode/DataNode/SecondaryNameNode)
start-dfs.sh
# 验证进程(核心!需看到以下3个进程)
jps
# 正常输出:
# NameNode
# DataNode
# SecondaryNameNode
# Jps
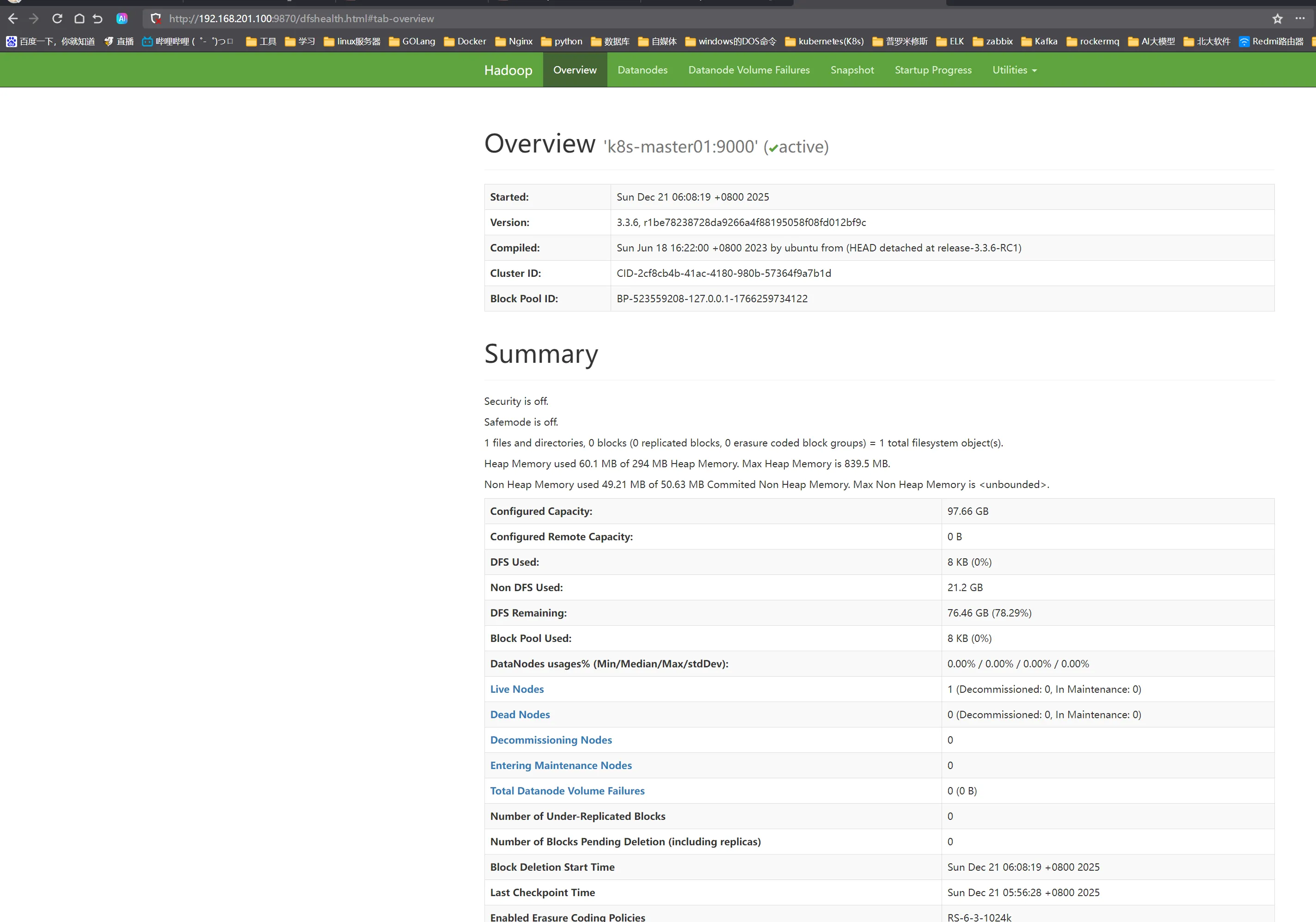
能访问就是成功了
测试能不能上传文件
js# 在hdfs创建一个songxuan的目录
hdfs dfs -mkdir /songxuan
# 上传本地家目录下的test.yml文件到hdfs的/songxuan目录下
hdfs dfs -put ~/test.yaml /songxuan/
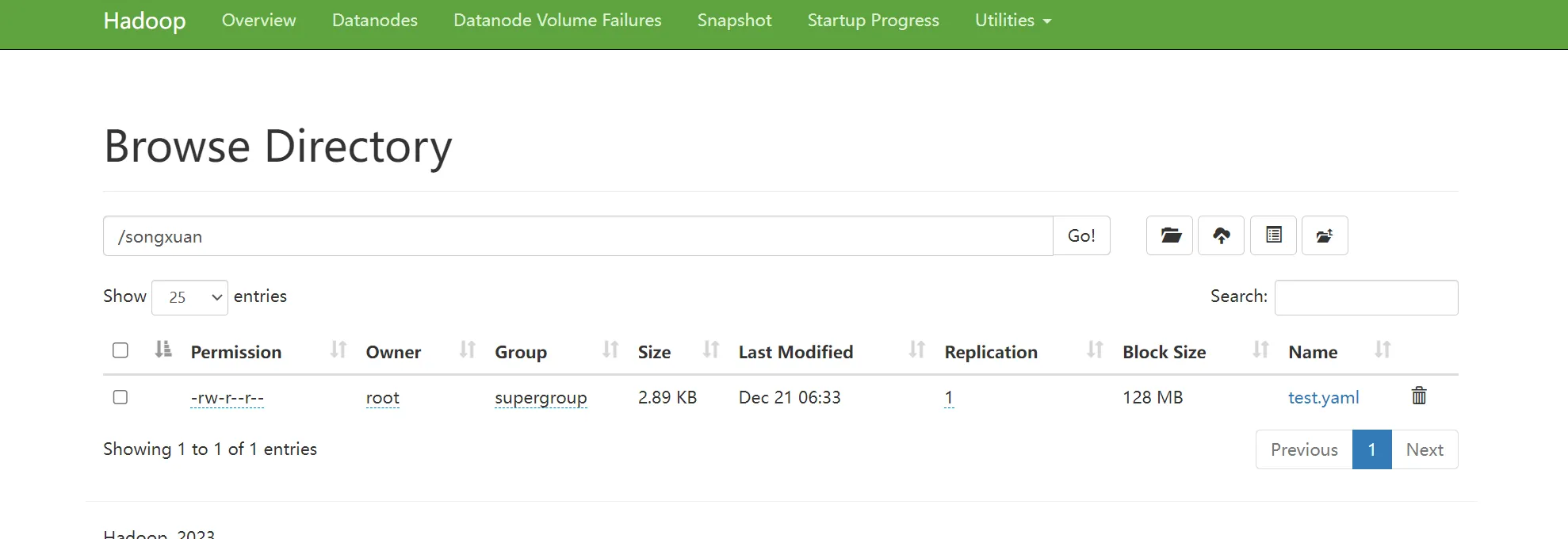
js# 查看是否有文件 fs -ls /songxuan/
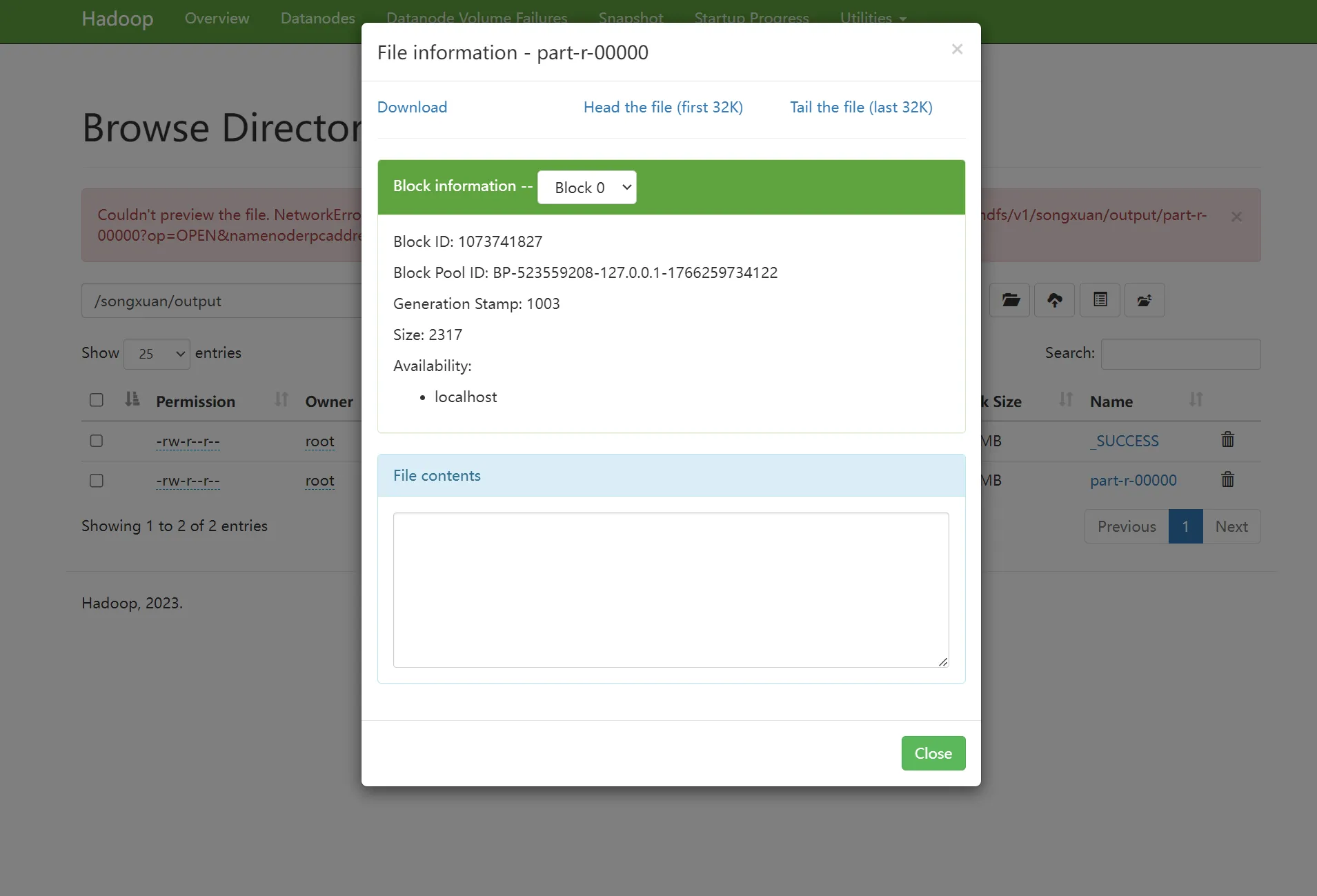
执行正确的 WordCount 命令
jshadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /songxuan/test.yaml /songxuan/output
js# 查看输出文件内容
hadoop fs -cat /songxuan/output/part-r-00000
本地Windows查看会报错,需要改配置
jsvim $HADOOP_HOME/etc/hadoop/core-site.xml
js<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!-- 指定HDFS的默认访问地址(主机名对应你的k8s-master01) -->
<name>fs.defaultFS</name>
<value>hdfs://192.168.201.100:9000</value>
</property>
<property>
<!-- HDFS临时目录(需确保root有读写权限) -->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-3.3.6/tmp</value>
</property>
<property>
<!-- 关闭权限检查(测试环境简化) -->
<name>hadoop.security.authorization</name>
<value>false</value>
</property>
<!-- ================ 新增配置(Windows访问必需) ================ -->
<property>
<!-- 开启WebHDFS功能(核心:支持WebUI查看/下载文件) -->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<!-- 指定WebUI默认操作用户(和运行Hadoop的root一致,解决403权限报错) -->
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<!-- 兜底关闭HDFS权限检查(避免WebUI操作被权限拦截) -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- =========================================================== -->
</configuration>
jsvim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
js<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.201.100:50090</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:9864</value>
</property>
<!-- 强制DataNode绑定服务器IP,而非127.0.0.1 -->
<property>
<name>dfs.datanode.address</name>
<value>192.168.201.100:9866</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>192.168.201.100:9867</value>
</property>
<property>
<name>dfs.datanode.hostname</name>
<value>192.168.201.100</value>
</property>
</configuration>
jsstop-dfs.sh
start-dfs.sh
# 验证进程(必须有NameNode、DataNode)
jps
本文作者:松轩(^U^)
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录