
Press Ctrl+ and K to search
请注意,本文编写于 180 天前,最后修改于 179 天前,其中某些信息可能已经过时。
目录
一、Hadoop介绍
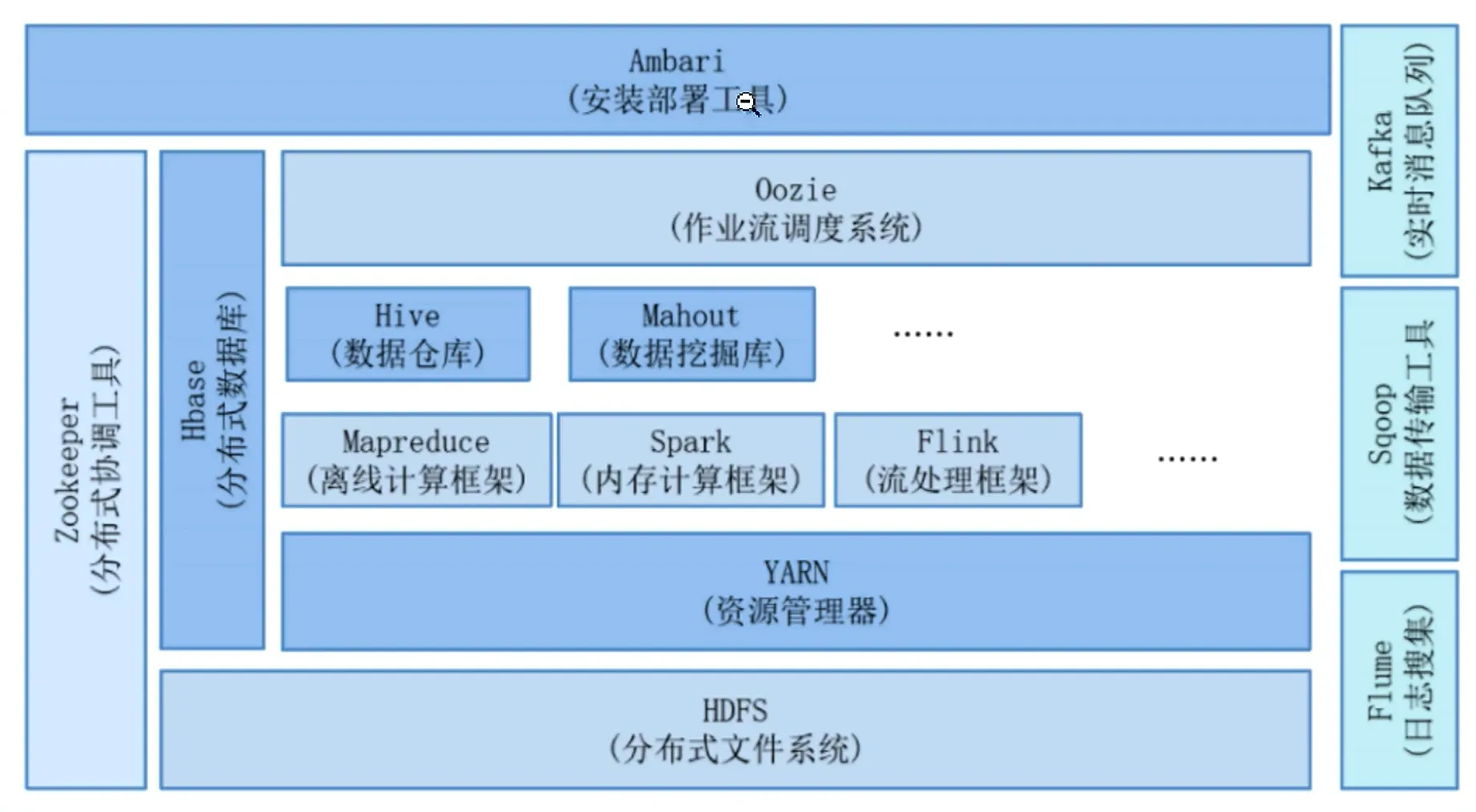
Hadoop 是一个开源的分布式存储与分布式计算框架,由 Apache 基金会维护,核心目标是高效、可靠地处理海量结构化、半结构化和非结构化数据。它的设计初衷是解决传统单机无法承载的大数据存储和计算问题,具备高容错、高扩展、低成本的特点。
Hadoop 的核心组成
HDFS(Hadoop Distributed File System)—— 分布式文件系统
js作用:负责海量数据的分布式存储,是 Hadoop 的 “数据仓库”。
核心特点:
分块存储:将大文件切分成固定大小的数据块(默认 128MB),分散存储在集群的不同节点上。
副本机制:每个数据块会生成多个副本(默认 3 个),存放在不同节点,保证数据容错性(某节点故障不会丢失数据)。
主从架构:由 NameNode(管理元数据,记录文件与数据块的映射关系)和 DataNode(存储实际数据块)组成。
局限性:适合一次写入、多次读取的场景,不适合小文件存储和频繁修改的操作。
MapReduce —— 分布式计算模型
js作用:负责海量数据的离线批处理计算,是 Hadoop 的 “计算引擎”。
核心流程:
Map 阶段:将任务拆分,多个节点并行处理局部数据,生成中间结果。
Reduce 阶段:汇总所有节点的中间结果,计算出最终输出。
局限性:处理延迟较高,不适合实时计算;只支持批处理,灵活性不足。
YARN(Yet Another Resource Negotiator)—— 资源调度与管理框架
js作用:负责集群资源(CPU、内存)的统一调度和任务管理,相当于 Hadoop 集群的 “操作系统”。
核心特点:
解耦了 “资源管理” 和 “任务运行”,支持多种计算框架(除了 MapReduce,还能支持 Spark、Flink 等)。
主从架构:由 ResourceManager(全局资源调度)和 NodeManager(单个节点的资源管理)组成。
Hadoop 的核心优势
js高容错性:依赖 HDFS 的副本机制和任务重试机制,节点故障不影响整体任务。
高扩展性:集群可以通过添加普通服务器节点,线性提升存储和计算能力。
高吞吐量:专为批处理设计,能高效处理 TB、PB 级别的海量数据。
低成本:可以运行在普通 x86 服务器集群上,无需昂贵的专用硬件。
二、下载安装Hadoop
先安装javaJDK8配置环境变量
js# 1. 找到你的OpenJDK 8安装路径(rpm安装的OpenJDK通常在以下路径)
find /usr/lib/jvm -name "java-1.8.0-openjdk*"
# 输出示例:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
# 2. 配置JAVA_HOME(永久生效,所有用户可用)
vim /etc/profile
# 在文件末尾添加(替换为你查到的实际路径):
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
export PATH=$PATH:$JAVA_HOME/bin
# 3. 生效并验证
source /etc/profile
echo $JAVA_HOME # 输出上述路径则正确
# 4.绑定本地主机
echo "192.168.201.100 k8s-master01" >> /etc/hosts # 绑定本机hosts
上传解压hadoop包
jsrz hadoop-3.3.6.tar.gz
tar -zxvf hadoop-3.3.6.tar.gz
继续配置环境变量
js# 直接编辑全局配置文件,Root 用户生效
vim /etc/profile
js# Hadoop 环境变量(Root 用户,路径:/opt/hadoop/hadoop-3.3.6)
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.6
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
js# 立即生效配置
source /etc/profile
# 验证 HADOOP_HOME 路径(必须和解压路径一致)
echo $HADOOP_HOME
# 正确输出:/opt/hadoop/hadoop-3.3.6
# 验证 Java 环境(确保 JAVA_HOME 正确)
echo $JAVA_HOME
java -version
# 验证 Hadoop 命令(无 "command not found" 则成功)
hadoop version
注意
因为我是rpm包安装的javajdk导致自动安装的目录不同所以要建一个软链接,
js# 先确认JAVA_HOME目录结构
ls -ld /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/bin
# 输出 "No such file or directory",所以先创建bin目录
mkdir -p /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/bin
# 核心操作:将实际的java可执行文件链接到Hadoop期望的路径
ln -s /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/jre/bin/java /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/bin/java
# 验证软链接是否创建成功
ls -l /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/bin/java
# 正常输出(指向jre下的java):
# lrwxrwxrwx 1 root root 76 月 日 时:分 /usr/lib/jvm/.../bin/java -> /usr/lib/jvm/.../jre/bin/java
chmod +x /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/bin/java
# 验证链接后的java是否可执行
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64/bin/java -version
# 输出OpenJDK 1.8.0_262版本则正确
# 重新生效环境变量(确保配置无缓存)
source /etc/profile
# 执行hadoop version
hadoop version
# 正常输出示例(无报错则成功):
# Hadoop 3.3.6
# Source code repository https://github.com/apache/hadoop.git -r 94261f61f91e2585fa572332d065983b1d113959
# Compiled by ubuntu on 2024-01-08T12:40Z
# Compiled with protoc 3.7.1
# From source with checksum 2e364f1415f31111a65788c9c93a0700
# This command was run using /opt/hadoop/hadoop-3.3.6/share/hadoop/common/hadoop-common-3.3.6.jar
本文作者:松轩(^U^)
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录